Opening the Black Box of Deep Neural Networks via Information
タグ: SGD learning theory
概要
[1703.00810] Opening the Black Box of Deep Neural Networks via Information
- DNNの解析
- 情報平面(Information Plane)という概念で学習パラメータのダイナミクスを解析している
- SGDによる学習は大きく2つのフェーズに分類できる
- 各層はEncoder-Decoder構造とする。入力 $X$, 潜在変数 $T$, 再構築された出力 $Y$。
3. Numerical Experiments and Results
- SGDでの学習パラメータのDynamics
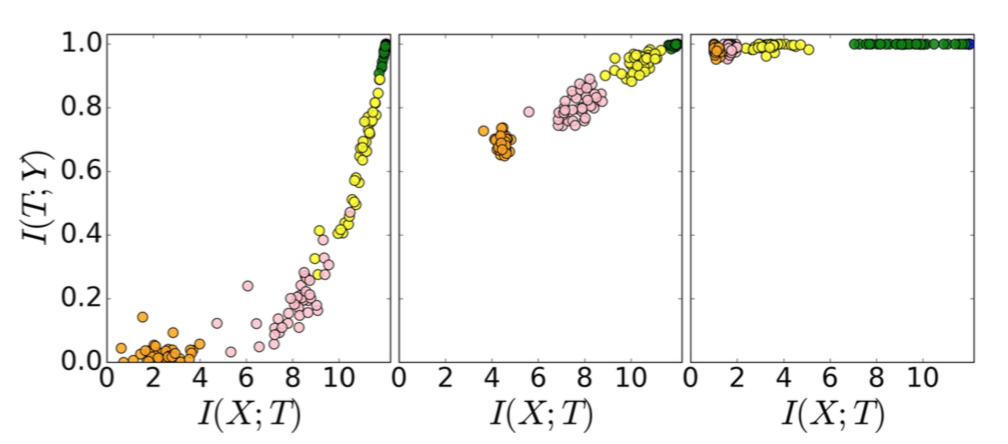
- 各色の点が各レイヤの出力。ランダムに初期化された50個のモデルを同時にプロットしているため、同じ色の点が50個プロットされている。
- 左: 学習初期。
- 中: 学習途中。
- TとYの相互情報量が上がっていく
- 右: 学習終盤。
- XとTの相互情報量が下がっていく
- compression phase
- ランダムに初期化したどのモデルも、同じようなパスをたどる
- 学習に使用したサンプル数とInformation Planeの関係
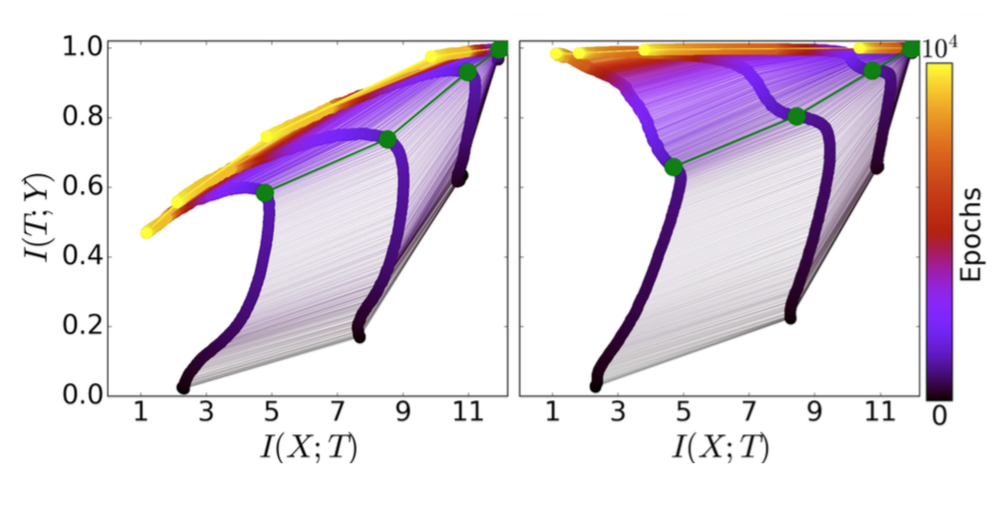
- 使用するサンプルのバリエーションが少ない(図左)と、compression-phaseで $I_Y$ が低下している
- Xが過度にcompressionされている。つまりoverfitが発生している。
- 緑のパスは、学習のフェーズが切り替わる点
- サンプル数が異なっても、緑のパスの位置は大きく変化しない
- 使用するサンプルのバリエーションが少ない(図左)と、compression-phaseで $I_Y$ が低下している
- SGDのGradientから見た2つのフェーズ
- Phase1: Drift Phase
- GradientのMeanがStdより大きいフェーズ
- Phase2: Diffusion Phase
- GradientのStdがMeanより大きいフェーズ
- Phase1: Drift Phase
- 隠れ層の数
- 層の数が増えるほど、必要な学習エポック数は減る
- なんで?
- 層の数が増えるほど、必要な学習エポック数は減る