SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
概要
[1609.05473] SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient
- 系列生成にAdversarial Lossと強化学習を利用
背景
時系列生成の現状の課題
- exposure bias (training/inference discrepancy)
- trainingの際は常に正しい文を入力されて次の語を予測しているがinferenceのときは自分の入力を食って次の語を出力することによるbias
- 一語ずつ尤度が高くなるよう学習してるけど全体として文になっているかどうかを見れているわけではない。
- BLEUscoreで評価する手もあるけどなんか微妙だし詩とか無理だよね
GANの時系列生成
- 通常のGANは離散系列に弱い
- Gの出力が離散値だとDからの誤差信号がbackpropしない。
- Dが評価できるのは文章も全部生成されてから。途中で学習できないから収束しなそう
本研究のIdea
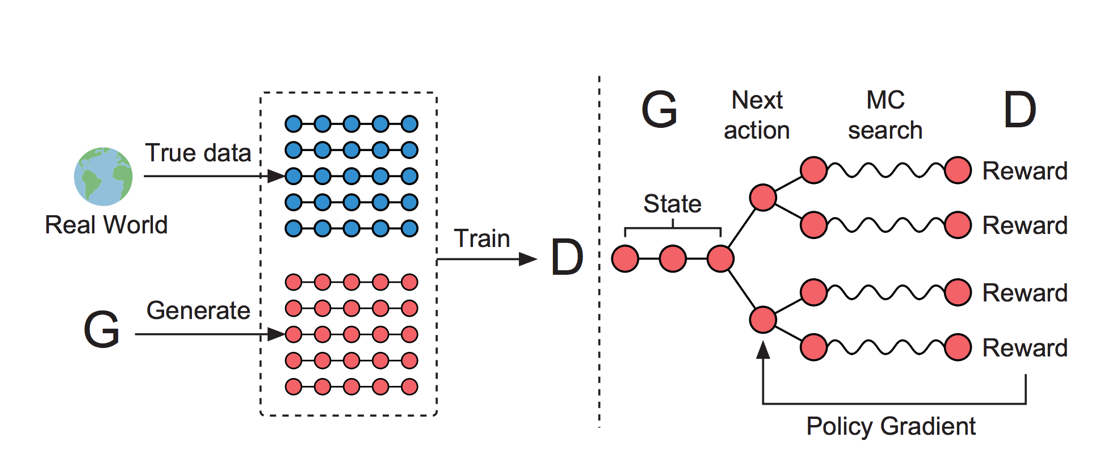
- 生成過程を、意思決定過程とみなす -> 強化学習の枠組みに落とし込む
- G (RNN) をそれまでに生成された文を状態sをうけとり次に一つの語aを出力するpolicyとみなす。
- D (CNN)は文章全体を入力とし、その分が本物か偽物かを判別
- 文の途中でも学習したいので、ある語$y_t$を選び、それ以降はMCsearchでrolloutして生成された文をDに入力したときの本物である確率を$y_t$を選ぶことの期待報酬とする。そうすると強化学習の普通のREINFORCE(方策勾配法)でGの学習ができる。
結果
- 簡単に評価できる人工データでやったら他の手法よりもかなり良い尤度
- 他にも詩とか演説とか音楽とか試し、より人間っぽいものが生成できた
感想
- すごく面白いと思います。