SORT: Second-Order Response Transform for Visual Recognition
タグ: CNN
概要
[1703.06993] SORT: Second-Order Response Transform for Visual Recognition
Second-Order Response Transform (SORT)
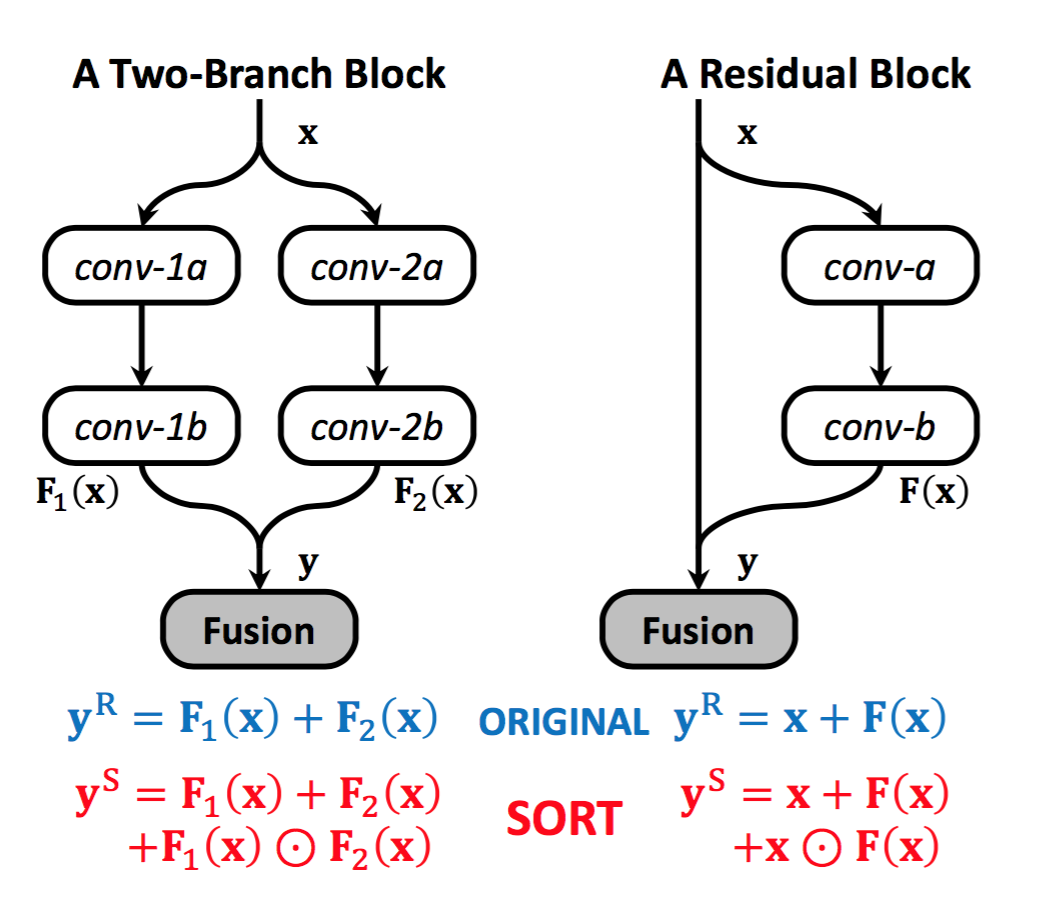
内部が2-stream構成で、$y_1 + y_2 + y_1 \odot y_2$を出力とするモジュール
なぜ単に2乗するのではなく2-streamにしたのか
この方が学習が安定する。 $F_1$ 側のbackpropの計算は $F_2$ 側の出力に依存するため、学習がサチりにくい。
なぜ足し合わせる(=ResNet)だけではなく、Element-wise productを併用したのか。
非線形性が高く、表現力が向上するから。
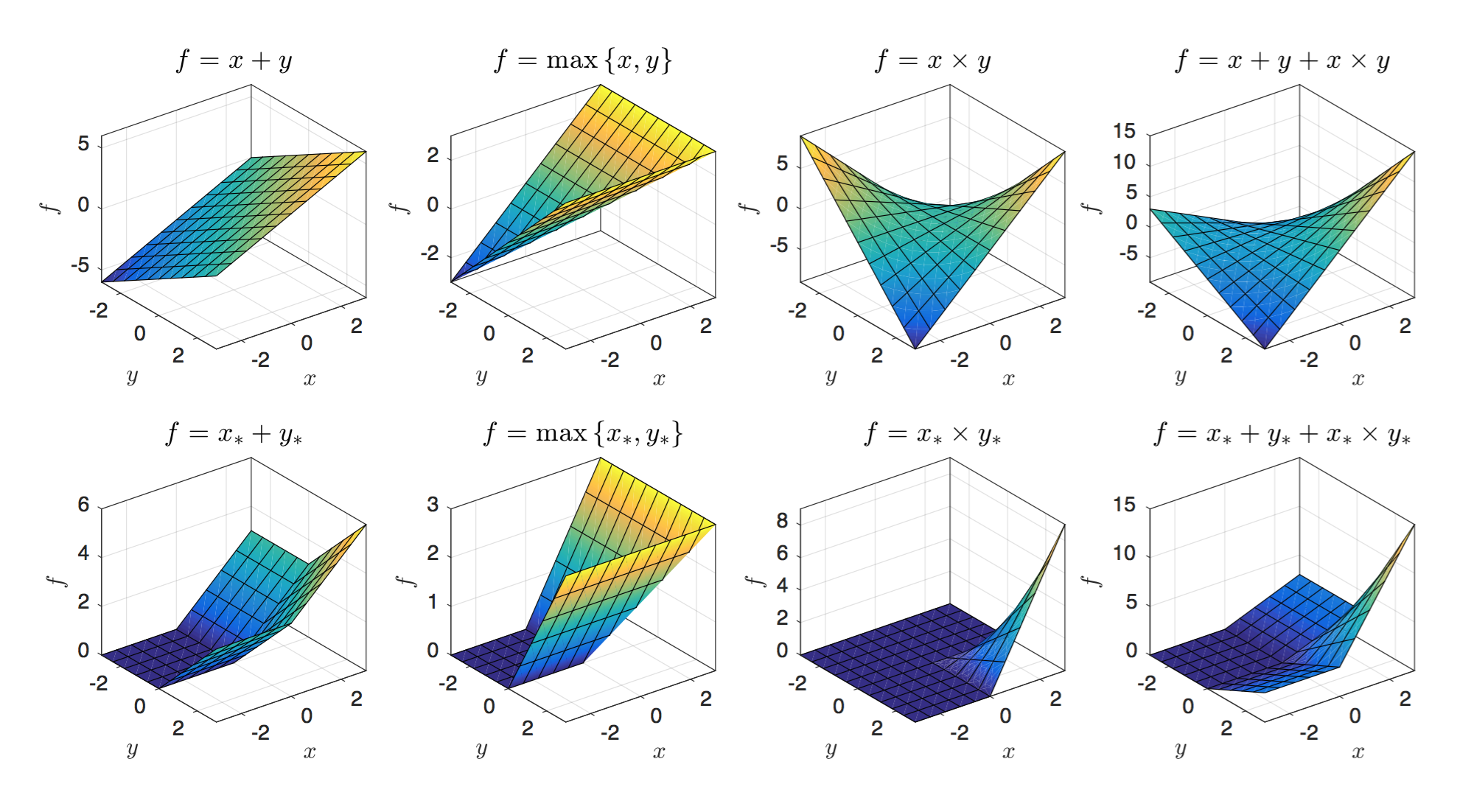
様々な変換における非線形性の比較。 $x_* = ReLU \left( x \right) = max \left( x, 0 \right)$。一番右下がSORT。
実験
既存のモデル(AlexNet, ResNet)にSORTを組み込んで色々な画像認識タスクで比較。CIFAR-10, SVHN(町並みの画像から家の数を当てるタスク), ImageNet。
結果、どれも精度が僅かに向上
思ったこと
- CNN特徴量の共分散を取るモジュールが効果があると言う話もあったがそれもこの論文の結果に内包されるのか
- こっちの論文では、一次と二次の項を足し合わせているが、あちらの論文では、別々の出力にしているという違いがある。どちらが良い?