Mask R-CNN
アーキテクチャ
- 通常のFaster R-CNN
- Region Proposal NetworkがRegion Proposalを出力
- proposalに対して次の2つの処理を行う
- それが何のクラスなのかを予測するlabel-branch
- bounding-boxのregressionを行うbox-branch
- Mask R-CNN
- segmentationを行う、3つ目のbranchを追加した
- 特徴抽出層(backbone)として何を使うかにより2種類のモデルを提案
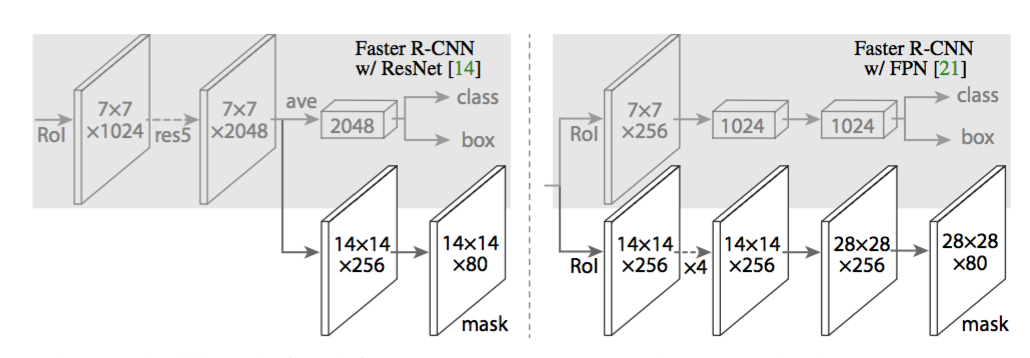
- Feature Pyramid Network (FPN)
- ResNet Conv4.x (C4)
実験1: Segmentation
データセット:MSCOCO
定性的な比較
FCIS++(上段)とMask R-CNN(backboneはResNet-101-FPN)(下段)

FCIS++では、重なった物体の予測に弱いという問題がある
活性化関数の違い
- FCNなどでは画像の全pixel毎に、全てのクラスの確率計算してsoftmax取っている
- 今回はlabel-branchでProposalが何のクラスなのかは既に予測している
- そのため、出力された1つのクラスについてのみ予測を行いsigmoidで学習した方が精度・学習速度ともに大幅に向上した
クラスを意識したセグメンテーションと意識しないセグメンテーション
- クラス情報無視してセグメンテーションしてもほとんど精度が変わらなかった(!)
- よって、label-branchとsegmentation-branchは並列化できる
処理時間
- FPNで195ms/image = 約5fps
- C4は遅い
- そもそもspeedはこのpaperの対象外
- 画像サイズやproposalの数を変えることで早く出来るだろう
- Mask R-CNNは学習も早い
- FPNの場合8GPUで約2日、プロトタイプ版は一日未満で学習できた
detectionの精度
- boxのdetectionの精度でもFaster R-CNNを上回った
- segmentation側のLossがbox-branchの学習にも効いている
実験2: Human Pose Estimation
- K個のキーポイントの推定を、K個のサイズ1の領域のsegmentation問題に帰着させた
- キーポイントのみ学習させても従来手法より精度向上、更に、キーポイントと人間のマスクと両方を同時に学習させるとより精度が向上した