Deformable Convolutional Networks
タグ: CNN segmentation detection
概要
- arXiv: [1703.06211] Deformable Convolutional Networks
- 解説ブログ記事: Notes on “Deformable Convolutional Networks” – Medium
- Convolution(及びPooling)のフィルタのサンプリング領域を動的に変化させる
CNNのGeometricな制約
- フィルタの適応範囲が固定されている
- scale invariantでない
- bounding-box baseな特徴抽出には使えるが、不定形な領域の特徴抽出に向いていない
Deformable Convolution
- offsetを計算して、フィルタのサンプリング領域を動的に動かす
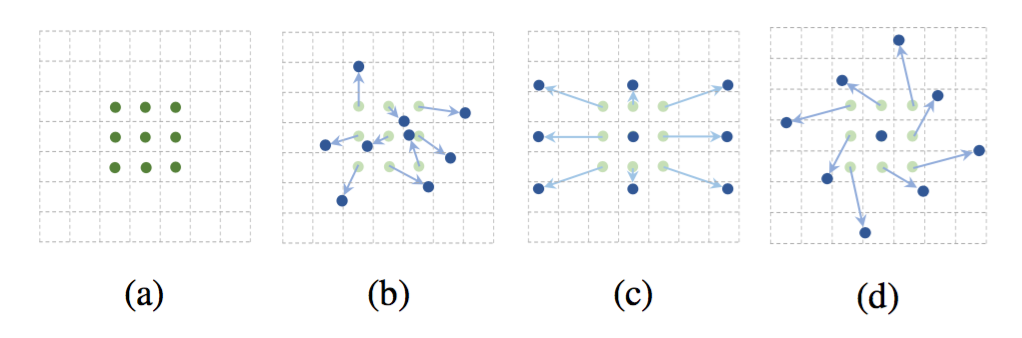
- a) 通常のconv
- b) deformable convolution(青矢印がoffset)
- c) 特殊なケース1:scalingに対応
- d) 特集なケース2:rotationに対応
- offsetは元のサンプリング領域から回帰によって求める
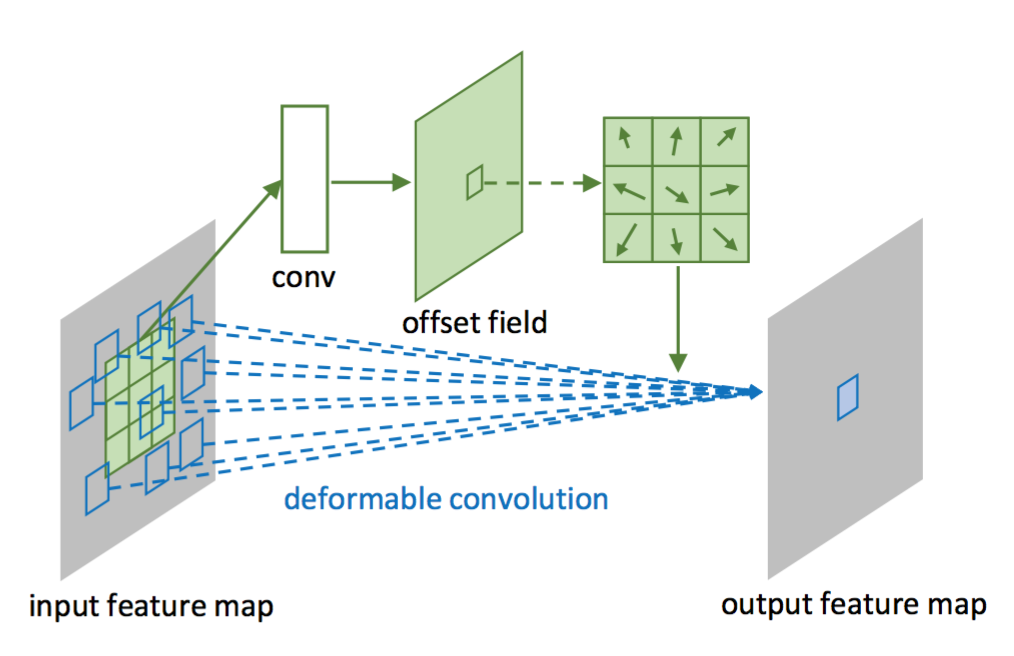
- offsetは整数とは限らないため、近傍のpixelから補完してサンプリングする
- offset計算モジュール側のbackpropagationはこの補完の式を元に行われる
- 学習がメチャクチャ不安定な気がする
Deformable RoI Pooling
- コンセプトはDeformable Convolutionと同じ
- オフセットベクトル $\mathbf{p} = \left( \Delta p_x, \Delta p_y \right)$ は入力特徴量の空間方向のサイズ $ \left( w, h \right) $ をかけた形 $\left( w \Delta p_x, h \Delta p_y \right)$ で利用する
既存アーキテクチャへの適用
- ResNet101とInception-ResNetへ適用
- ImageNetで学習済みのモデルを使用
- ネットワーク構造に以下の変更を適用
- poolingを取り払った
- 特徴行列の解像度が高いほうが本手法は有利
- conv層のstrideを全て1に設定
- 特徴行列の解像度が高いほうが本手法は有利
- fc層への入力サイズを揃えるために、fc層の直前に1x1のconvolution(projection)を入れた
- 最後の3つのconv層をdeformable convolutionに変更
- poolingを取り払った
定量評価
- Deformable-Convolutionの有無で精度を比較
- Semantic Segmentation
- PASCAL VOCとCityScapesというデータセットを使用
- Object Detection
- PASCAL VOCとCOCO
- ResNet101で特徴抽出した後、色々な手法に突っ込む
- Semantic Segmentation
- どのタスク・手法でも精度向上。基本的にはDeformable Convolution層が多いほど精度向上
- フィルタサイズ3x3のconvolution3層がサンプリングした、 $\left(3 \times 3 \right)^3 = 729$ 個のpixelの位置

- 赤色がサンプリング点、緑の矩形がフィルタの中心位置
- 3枚の画像は左から順に、背景、小さな物体、大きな物体について見てみた例
- dilation sizeが認識対象物体の種類・画像中の大きさ(スケール)に合わせて調整されている
- 単に、ResNet101のdilation sizeを変えてみたらどうなる?
- モデル・タスクによって最適なdilation sizeは違った
- dilation sizeの学習は重要といえる
- Deformable RoI Poolingも併用したら更に精度向上した
- 計算量・モデルサイズはほとんど変わらない
- おかしい。動的なインデックス計算を挟む分、圧倒的に遅くなるはずでは?
関連研究との比較
- Spatial Transform Networks (STN)
- Spatial Transformを学習するという点で関連がある
- STNでは、特徴行列をアフィン変換で変形することを考え、そのパラメータを学ぶ
- パラメータ学習とオフセットの学習という点で異なる
- Spatial Transformを学習するという点で関連がある
- Effective Receptive Field
- 受容野(=フィルタのサンプリング領域)の中心に近いほど、出力への寄与が大きいと考え、受容野に2次元ガウシアン状の重みを加味する手法
- Deformable Convolutionでも同様に、フィルタの中心に近い所から重点的にサンプリングされている
- Atrous Convolution(Dilated Convolution)
- カーネル中のサンプリング位置のストライドが2以上のConvolution(説明が難しい。フィルタサイズk=5で、x=0, 2, 4からサンプリングする、みたいな。)
- Deformable Convolutionはこれの一般化と言える
- Spatial Pyramid Pooling
- Deformable RoI Poolingと同様、様々な大きさ(縮尺)でPoolingする
- スケールがハイパーパラメータか、End-to-Endで学習できるかという違いがある
- Dynamic Filter
- 入力された特徴行列によってフィルタを動的に変える手法
- Deformable Convolutionとは異なり、サンプリング位置は学習していない
気になったこと
- 学習時間はどれくらい?安定して学習できるのか?