Smart Augmentation - Learning an Optimal Data Augmentation Strategy
[1703.08383] Smart Augmentation - Learning an Optimal Data Augmentation Strategy
概要
- DNNの汎化性能をあげるための手法として、Smart Augmentationを提案
Smart Augmentation
- 2種類のネットワークを用意
- 学習時はランダムに3つ、同じラベルのサンプル3個($x_1, x_2, x_3$)を使用する。
- データ生成用network(A)
- $x_1, x_2$を入力として、新しいサンプル$x_4$を出力する。
- ロス関数$L_A$はMean Squared Error, $MSE(x_3, x_4)$。
- データ識別用network(B)
- 本来のタスク(画像識別など)用のネットワーク。
- $x_3, x_4$を入力として学習する。
- ロス関数 $L_B$ は一般的なもの。cross_entropy_loss など。
実験結果
- グレースケール顔画像(正面)の男女識別
- 生成されたサンプルの例
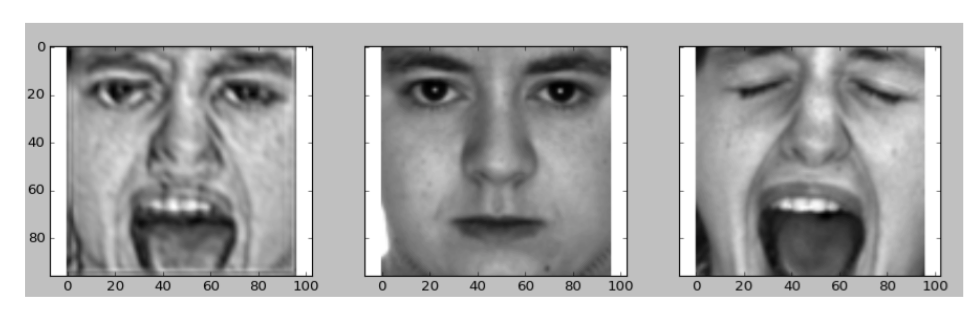
- 一番左の画像は右の2つをブレンドして生成された
- 学習曲線
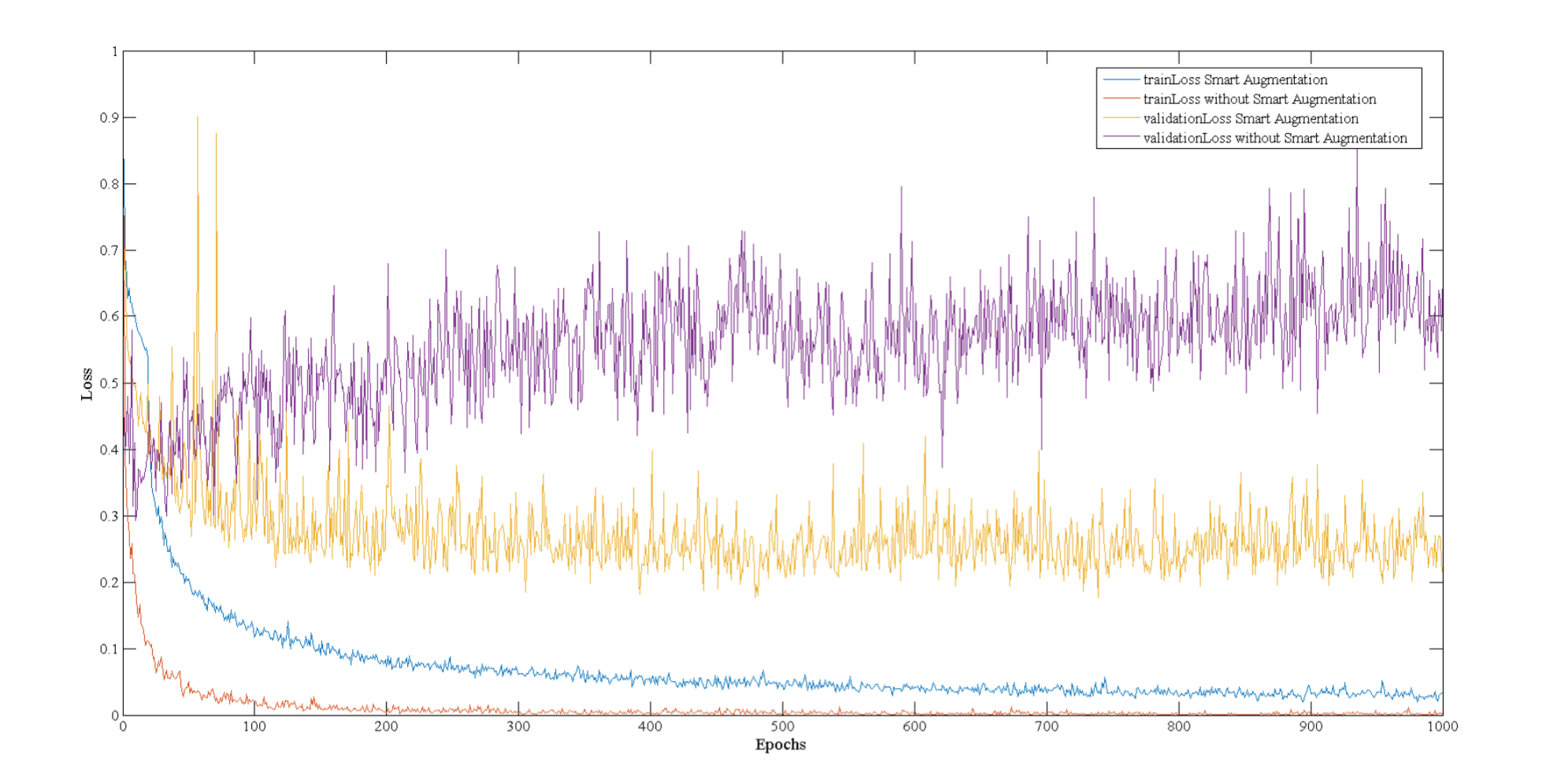
- Smart Augmentation無し(train:赤, valid:紫)では、10epochあたりから過学習が発生してvalidation lossが増加している
- Smart Aumentation有り(train:青, valid:黄)では、学習は遅いが過学習が発生せず、最終的にSA無しよりもvalidation lossが小さい
- 生成されたサンプルの例
思うこと
- $L_A$ は何故MSEなのか?
- どのようなサンプルがBの汎化性能を上げるために重要なのかは、Bのstate(=weight)に依存しそうだが、これらを入力としなくて良いのか?
- Bのweightをstate, iteration前後でのBのlossの減少量をrewardとした強化学習とかのほうが自然な気が
- 同じクラスの2つのサンプルをブレンドしたからと言って、必ずしも同じクラスになるとは限らないのでは