Deep Reinforcement Learning-based Image Captioning with Embedding Reward
概要
Deep Reinforcement Learning-based Image Captioning with Embedding Reward
- 従来のキャプション生成はencoder-decoderモデルが多いが、
- “Policy Network”と”Value Network”を用いた強化学習によるキャプションの生成
- 性能良い
手法
- $ S=\{ w_1, w_2, \dots, w_T \} $ : sentence (文のstep:tにおける生成過程を、状態Sと定義)
- $a_t=w_{t+1}$ (actionは次の単語)
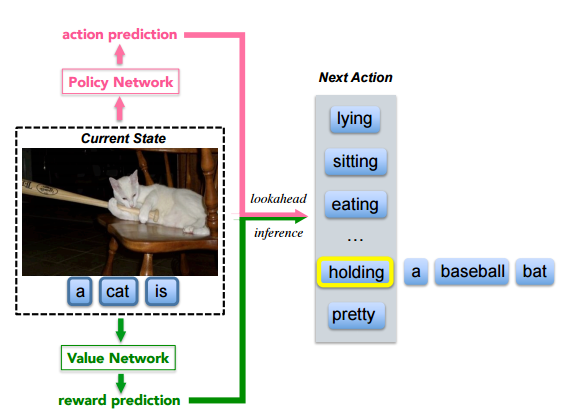
Policy Network,Value Networkは共に1段階目はは別々で学習させて、次に結合させて学習
Policy Network
$p_π( a_t | s_t )$ : 状態$S_t$においてどのようなactionをとるべきかを予測
探索の木の幅を絞る役割
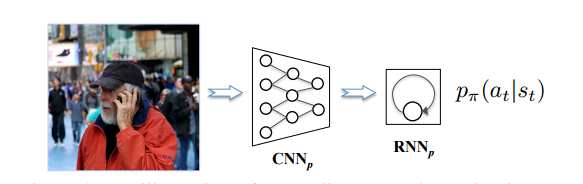
- 1. 画像を$CNN_p$によってencodeし、それを$RNN_p$に入力するための次元に変換して入力
- 2. $RNN_p$ の出力を単語の次元に変換して、方策 $p_π(a_t|s_t)$ を求める
1段階目の学習 : 教師ありでcross-entropy lossによって学習させておく
Value Network
$v_\theta(s_t)$ : 状態Stの価値を見積もる
探索の木の深さを絞る役割
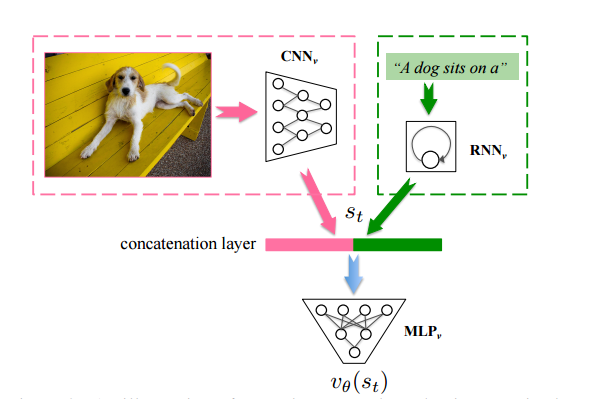
- 1. 画像を $CNN_v$ によってencodeする
- 2. $RNN_v$ によって現在までのsemanticな情報を出力
- 3. 上の2つをconcatして $MLP_v$ にかけ、状態$S_t$の価値を推定する
1段階目の学習 : まずランダムに選択した生成過程における価値が最終的なReward(文とキャプションの対応度合いを表す)と一致するように学習
を最小化
Rewardについて
画像と文章のペアが以下によって同じsemantic embedding spaceに写像されるように学習させたものを用意
- 画像 : $CNN_e$から抽出した特徴量vを$f_e$(linear mapping layer)にかける
- 文章 : $RNN_e$の最後の出力$h^\prime_T(S)$を出す
以下のロスにて学習
$S^-$ : 画像に対応していない文のこと
$v^-$ : 同様
- 画像とキャプションが対応 -> 内積を大きく
- 画像とキャプションが対応していない -> 内積を小さく
(交差検証によって決定したmargin βを設ける)
また、Rewardは以下の用に計算
Policy NetworkとValue Networkをつなげて学習
partially observable Markov decesion processと見て、以下の用に勾配を計算
これはactor-critic($p_π$:actor,$v_\theta$:critic)の関係としても見ることができる。
しかし、やはりactionの候補が単語の種類分あると、選択肢が膨大になりすぎて学習がうまく行かない。
- そこで、Curriculum Learning の導入
初めの(T-i×Δ)単語はクロスエントロピーで、残ったi×Δ単語を強化学習で (i=1,2,…と増やしていき、徐々に全文を強化学習で生成するようにシフトしていく)
Lookahead inference with policy network and value network
Beam Searchを用いる(従来のキャプション生成にもあったが、幅優先探索を行いつつ、ビーム幅個のノードを保持して評価値の低いものは捨てていくもの)
$W_{[t]}$ : t単語目でのBeam Searchで残っているもの(t単語のかたまりがbeam幅数分) 定式化すると、
となる。このもとで、次のbeam sequenceは以下の用に定義できる。
従来のものは、このS(・)は生成された一連のlog確率を表していた。 これは、良いキャプションの中の全ての単語のlog確率は、このtop群に含まれるという仮定に基づくが、必ずしもそれは正しくない。 (ALphaGoも低い確率の行動も選択していた)
そこで、PolicyとValueを組み合わせた、先読みをした推論を以下の用に定式化
$w_{b,[t]}$のsequenceに対するスコアに、$w_{b,t+1}$の単語が加わったもののスコアを求めるので、
- Policyによる$w_{b,t+1}$の確信度
- Valueによる$w_{b,t+1}$が加わったときの評価
の2つをλ:1-λの割合で加えたもの
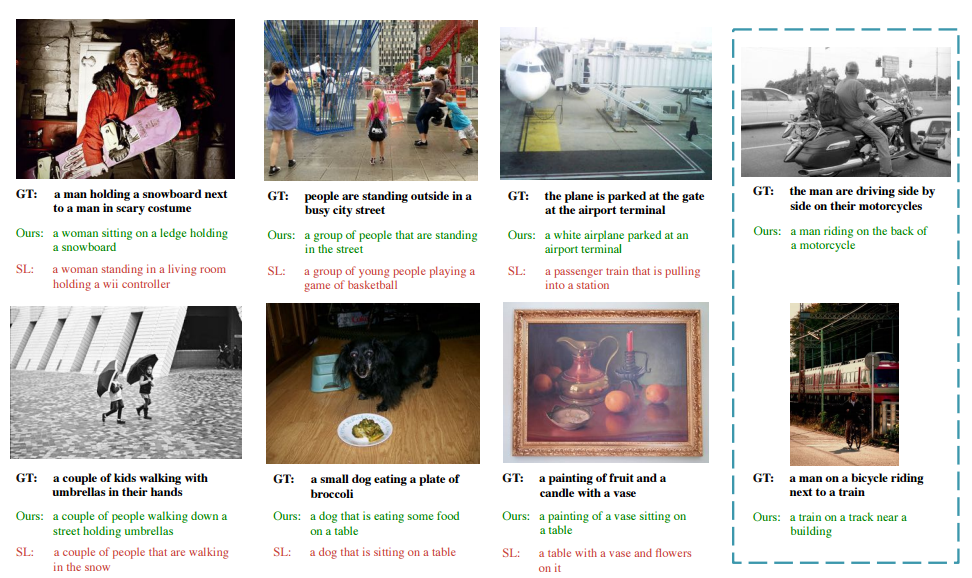
result sample