Efficient Sparse-Winograd Convolutional Neural Networks
タグ: CNN acceleration ICLR2017
概要
- Efficient Sparse-Winograd Convolutional Neural Networks
- Winograd convolution[Lavin+, 2015]は入力行列$ X $とカーネル行列$ W $を変形することで乗算回数を最小化し、高速化を図る
- この変換により、もとの行列$ X, W $のスパース性が失われてしまうため、スパース化による高速化とwinograd-convを直接組み合わせることは不可能だった。
- 元の空間でカーネルがスパースになるのではなく, Winograd空間に飛ばした先でスパースになるように $ W $ を正則化する ことでこの問題を解決した
- ICLR2017 workshop
詳細
全体像
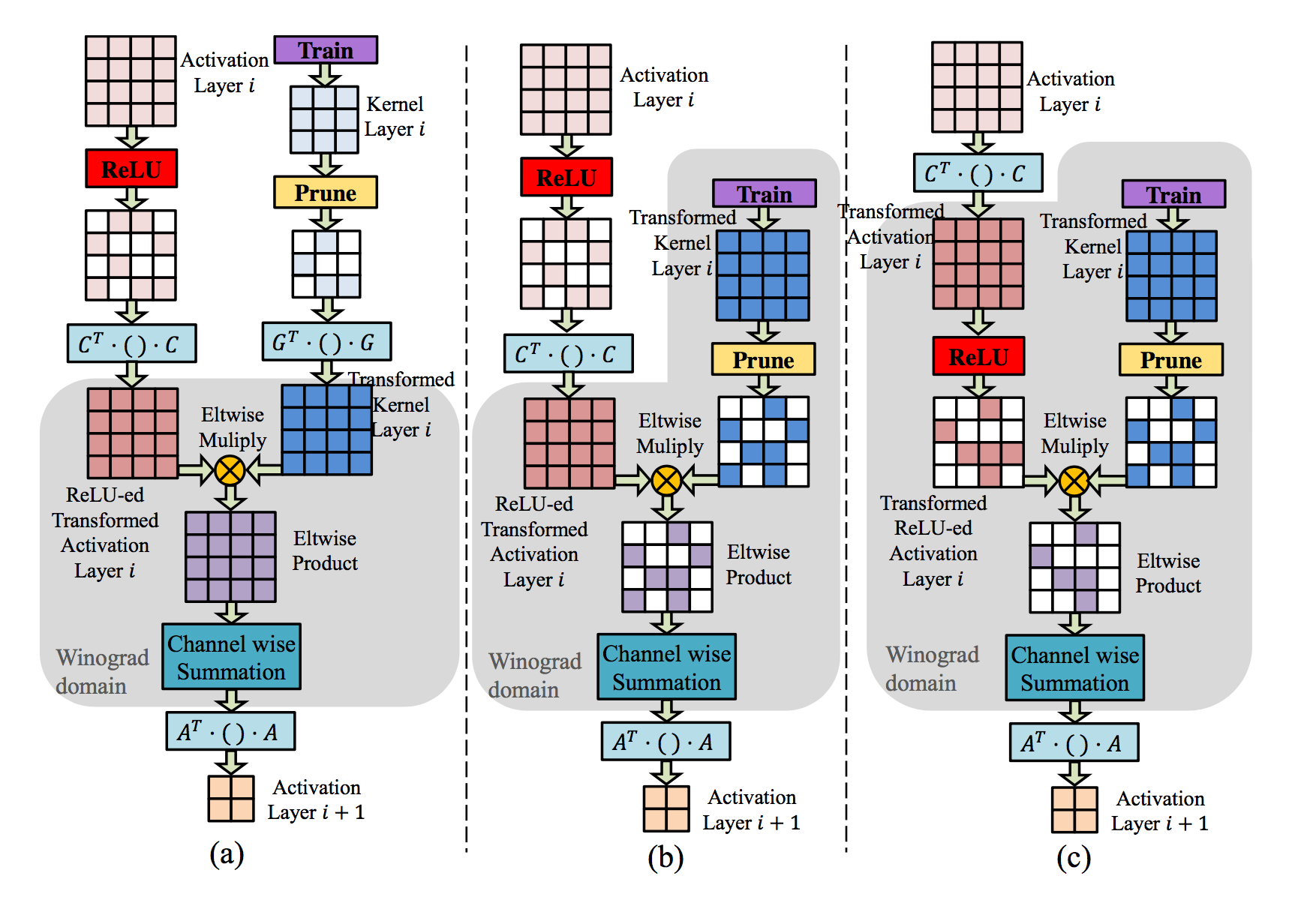
- a: 従来のWinograd-conv。2段目から3段目への変換($ C^t \cdot X \cdot C, G^t \cdot W \cdot G $)によって、スパース性が失われてしまう
- b: 提案手法1。予めカーネル行列をWinograd-domainに飛ばした上で枝刈りを行うため、スパース性が失われない。
- c: 提案手法2。提案手法1に加え、さらにReLUをWinograd-domainで行う。これにより$ X $側にもスパース性が現れる。
結果
- VGG + CIFAR-10で実験
-
denseで学習後、枝刈りを行った上でfine-tune
- Density vs Accuracy
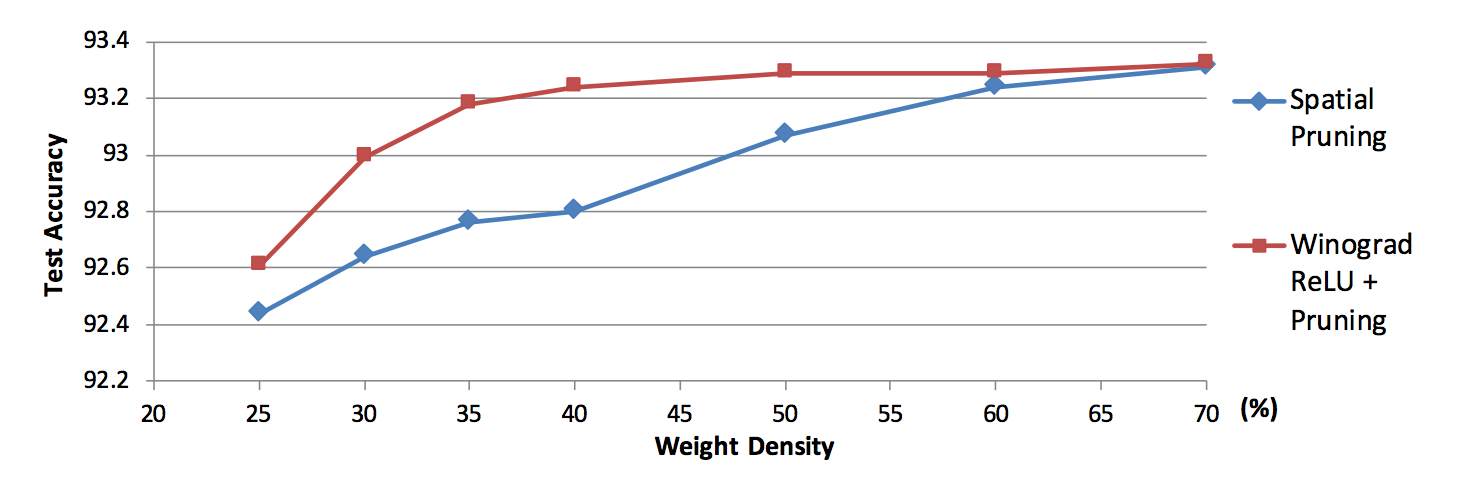
- density40%台までほぼロスゼロでsparse化できた。従来だと60%ぐらいまでしか行かないらしい。
- Winograd-domainへReLUを持っていったことの副産物
-
計算量
手法 乗算回数 向上比 original $ 2.3 \times 10^8 $ 1.0 pruning $ 4.6 \times 10^7 $ 4.6 winograd-conv $ 1.1 \times 10^8 $ 2.2 winograd-conv + relu $ 2.3 \times 10^7 $ 10.2 - winograd-domainへReLUもKernelも持っていくことで、乗算回数が1/10に抑えられた。
感想
- 実時間測定がないのは、やはりスパース化によるメモリアクセスの断片化が大きいのだろうか。
- 同じようにブロックスパース化をwinograd-domainでやれば実時間でも有利になるのでは