Person Search with Natural Language Description
タグ: Retrieval
概要
Person Search with Natural Language Description
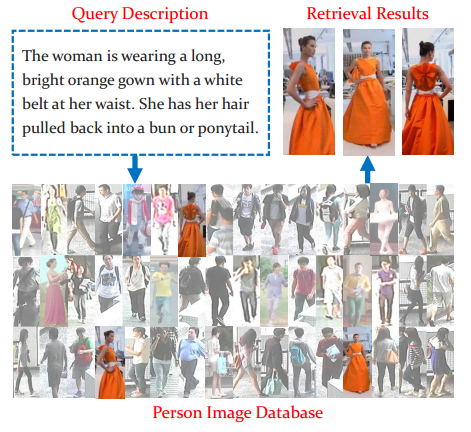
- 人の画像を自然言語の記述によって検索する
- 既存の手法は画像/attributeベースにとどまり、実用するには制約が大きい
- Recurrent Neural Network with Gated Neural Attention mechanism (GNARNN) の提案
手法
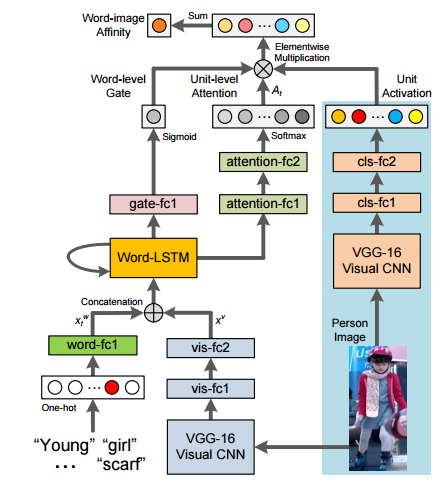
3つのunitによって構成される。
Visual Units
(上図右)
- VGG16のモデルで初め人を識別させ、これをVGG-16 Visual CNNと呼び、この重みは固定する
- VGGの”drop7”の後に512unitsのfc層を二つ足し、512次元のVisual Units( $ v = [ v_1 , \dots ,v_{512} ]^T $ )を出力
- このvisual unitsは全体の学習の中で自動的に人の外観のパターンを表していくようにする。
Attention over visual unutis
(上図真ん中)
文と写真のaffinityを計算したいので、単語ごとでVisual Unitsのどこにattentionを向けるかを学習
※例 ”white scarf”といったらそれに一致するVisual Unitsに重きを置いてほしい。
- 文章の各単語をembedding feature $ x_w^t $に変換し、上と同様にして得られたvisual feature $ x_v $をconcatし、LSTMに入力
- LSTMの隠れ状態$ h_t $を2層のfc層に通し、softmaxをかけて512次元のベクトル$ A_t $を出力する
- Visual Unitsのどこに重きを置くかを$ a_t = A_t \cdot v $により計算
Word-level gates for visual units
(上図左)
単語によって重みも変えるべき
※例 ”this” と “white” では単語の重要度が違う
- 隠れ状態$ h_t $ を1層のfc層に通し、sigmoidをかけることで単語の重要度$ g_t $を得る
- $ \hat{a_t} = g_t A_t \cdot v $によって単語レベルでの文と画像とのaffinityが計算でき、後は和をとればよい
training
文が対応していればaffinityの教師データ $ y^i $を1、対応していなければ0として、
クロスエントロピーで、
によって学習
結果例
