Beating Atari with Natural Language Guided Reinforcement Learning
概要
Beating Atari with Natural Language Guided Reinforcement Learning
- スタンフォードの授業の課題における最優秀賞
- 強化学習において、報酬がめったにもらえない状況(sparse reward)では学習が難しい
- 人間は完全に闇雲に動かすわけではなく他人からinstructionをもらう
- agentに自然言語によるinstructionを与え、それらが達成できたら報酬を追加で与える
- 常にcurrent instructionが与えられ、達成したら次のinstructionを目指す
流れ
- BreakOutにおいて、Auxillary reward (台がボールに当たったら得点、ボールを落としたら原点)を与えてちゃんと学習がはやくなるのか確認
- 前半の学習は速くはなった。しかし後半はむしろしないほうが最終的にスコアがよくなる
- 教えすぎると良くない。というかBreakOutはsparse rewardじゃないから意味がないのでは?
- でも有効っぽいことは確認
- Instructionをどう扱うか
- multimodal embeddingと呼んでいるが、フレームとinstructionを共通の空間におとす
- 適当にプレイを行い、その状況を適当にhard codingで説明することで(フレーム、instruction)のペアを作成
- それぞれCNN,LSTMでベクトルで分散表現に落とす。
- 適当な組み合わせでペアを与え、instructionとフレームの組み合わせが正しかったらそれらの内積を正、正しくなかったら負になるように学習を行う
- 学習結果をいろいろ試した結果、特定の状況に関して覚えてるわけじゃなくてちゃんと見たことがないところでも正しくinstructionの意味をわかってる感があったらしい。
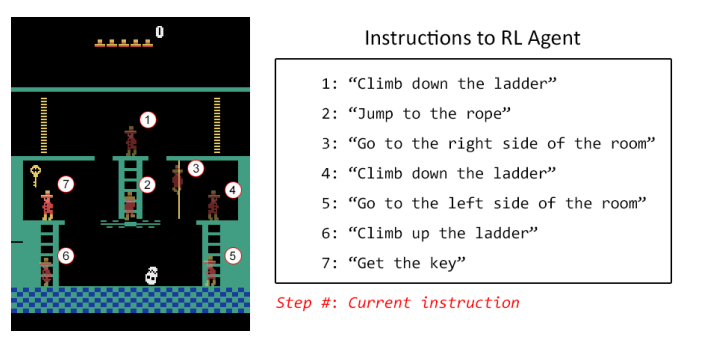
- Montezuma
- A3C (大人気のアルゴリズム)では、3日回してもaverage reward 0. (本当にmontezumaは難しい)
- まずはinstruction使わずにbreakoutで試したauxillary rewardで学習するとましになった。
- 普通に自分たちで遊んで15,000フレームとそれらに対応するinstructionのデータ・セットを学習 (labelづけは人手でつけたわけじゃないがhard coding)
- 先程説明したmultimodel embedding上で、現在のフレームと現在のinstructionの分散表現の内積が正になったら達成されたと見なして報酬を受け取るとともに次のinstructionへ
- result
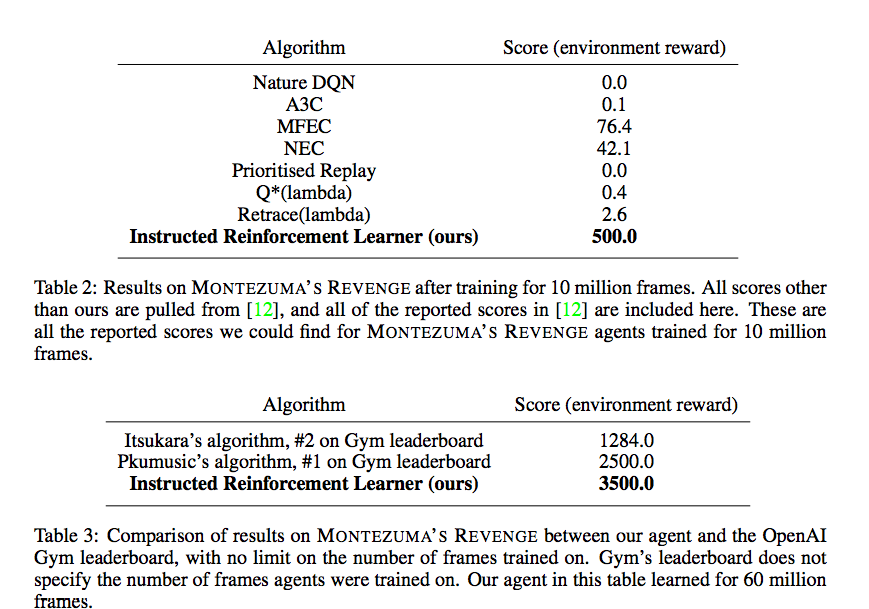
- 10 million frame後という制約ではぶっちぎり
- open ai gym リーダーボードで一番
- ほかの論文では6600というのもいるらしい
感想
- 面白い (内積のところホントにうまくいくのかはあやしいが)
- しかし順番に何らかのタスクをクリアする系のゲームじゃないとこのままだと使えない
- でも未来はありそうな研究だと思います