On-the-fly Operation Batching in Dynamic Computation Graphs
タグ: Framework
概要
-
[1705.07860] On-the-fly Operation Batching in Dynamic Computation Graphs
-
RNNではさサンプルの時系列長が異なるため、単純にミニバッチ処理はできない
- [解決策1] 1サンプルずつ処理していく
- 長所: 簡単
- 短所: 遅い
- [解決策2] ダミーデータをパディングした上で、ダミーデータによるロスをマスクする
- 長所: 効率的
- 短所: 実装が煩雑でバグの元
- ユーザーが[解決策1]のように実装しても、自動的にミニバッチ処理してくれるアルゴリズムを提案
アルゴリズム
- [解決策1]の要領で、N(バッチサイズ)個の計算グラフを構築
- 同じ処理をする計算グラフノードをマージし、バッチ処理する
- マージできる条件
- ハイパーパラメータの値が等しい
- 例えば、カーネルサイズの異なるconvolutionを一つにまとめることはできない
- 入力データが、メモリ上で連続的に配置されている
- 配置されていないと、これは結局バラバラに処理していることと等しい
- この論文では、メモリ上の配置を確認し、必要ならデータのコピーを行ってメモリ上に連続的に配置し直している。メモリ割付をスケジューリングしてうまい具合に連続的に配置されるように、といったことはしていない。
- ハイパーパラメータの値が等しい
- マージできる条件
- マージの戦略
- 時系列長3と4のサンプルをRNNに流す場合を考える
a1 -> a2 -> a3 -> Loss_ab1 -> b2 -> b3 -> b4 -> Loss_b
- depth-base
- 各時刻について、マージ可能なものをマージする。
- 例の場合、
[a1, b1], [a2, b2], [a3, b3], [Loss_a], [b4], [Loss_b]のようにマージされる - 時刻は違うが同じ処理(上の例の
Loss_aとLoss_b)はマージされない。
- agenda-base
- 時刻がずれていても、マージ可能ならマージする。
- 上の例の
Loss_aとLoss_bもマージされる。
- 時系列長3と4のサンプルをRNNに流す場合を考える
結果
手動バッチ化と自動バッチ化の比較
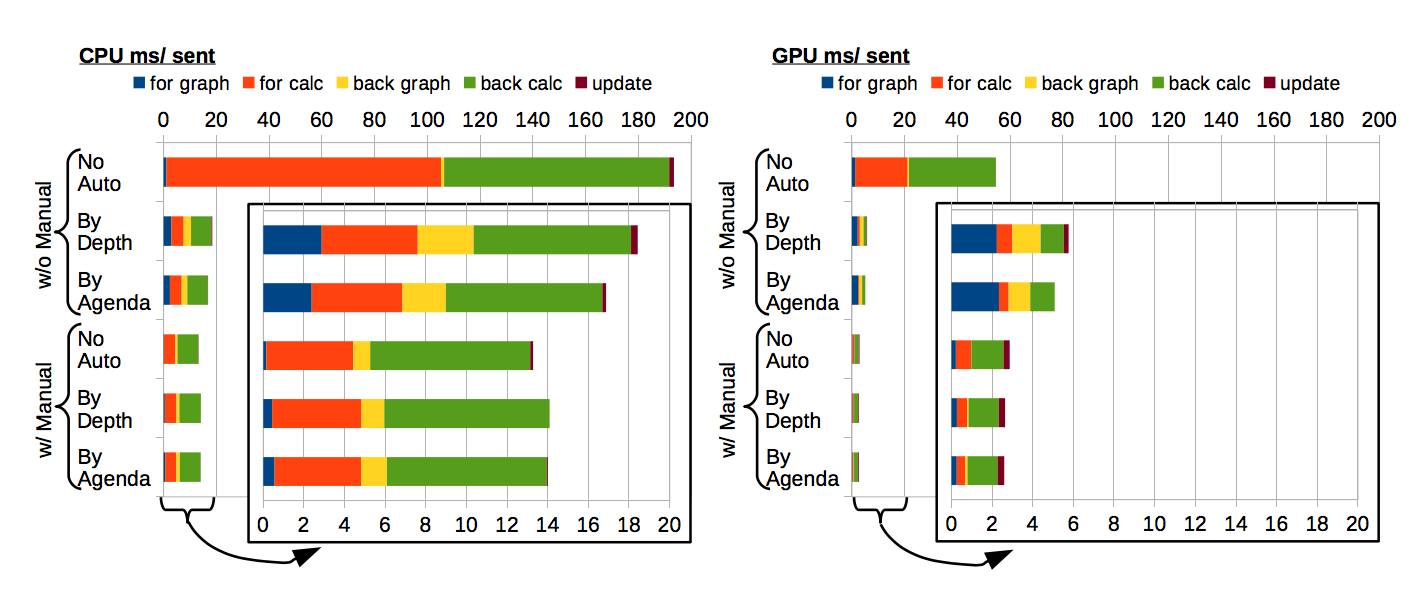
- w/o Manual No Auto が一切ミニバッチ処理しない例(=[解決策1])、
- w/o Manual By Depth および By Agenda が、提案手法のみをやった例
- w Manual No Auto が[解決策2]、
- w Manual By Depth および By Agenda が提案手法を手動バッチ化と組み合わせた例
いえること
- 自動バッチ化にはオーバーヘッドが有る(青色、黄色部分をNo Autoと比較)
- 手動バッチ化せずに全サンプルに対してマージをしようとすると、計算グラフ構築に時間がかかりすぎる
- 手動バッチ化と組み合わせることで計算グラフ構築の時間は減らすことが出来る。
- GPUだと自動マージを用いることで早くなる
- マージ処理はCPUで行われるので、マージをCPU、実計算をGPU、といったように役割分担できる。
TensorFlowと比較
- TensorFlow+Foldは、上述のdepth-base strategyのこと。
- DyNet+autoは、上述のagenda-base strategyのこと。
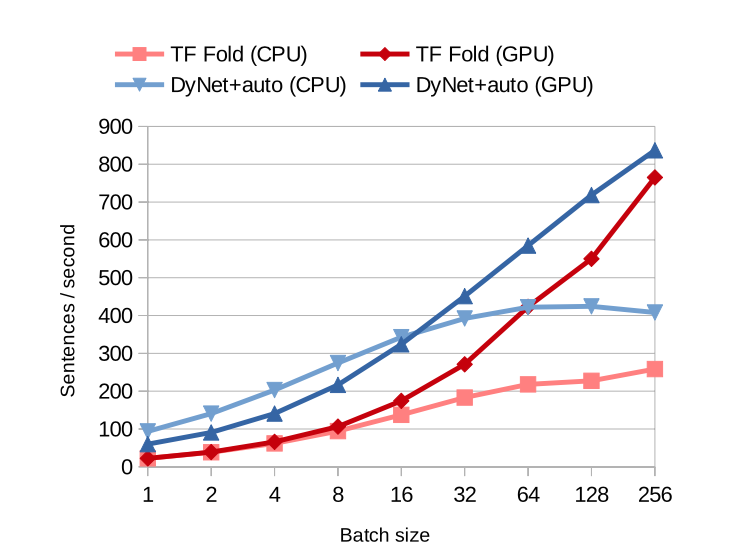
- TensorFlowより、CPU,GPUともに優れている。
- バッチサイズが増えれば、計算グラフ構築の際のオーバーヘッドも増加するので、auto-batchはどこかで効率が上がらなくなる点がある(今回のCPU, batch-size 64のあたり)
- ただ、現実的なバッチサイズの範囲なら問題ないとも言える。
思ったこと
- これは、TensorRTのhorizontal-fusionをランタイムに行っている、と捉えることができる。